
加密后存储
hashlib.sha1
布隆过滤器
布隆过滤器的应用场景:
- 网页黑名单系统
- 垃圾邮件过滤系统
- 爬虫网址的去重
对空间要求比严格,同时能够容忍一定程度的失误率。
布隆过滤器可以精确的代表一个集合,可以精确的判断某一元素是否在此集合中。而精确程度取决于具体的设计,100%精确是不可能的,能够在0.01%错误率是可以接受的。
布隆过滤器的优势是利用很少的空间就可以将正确率做到很高。
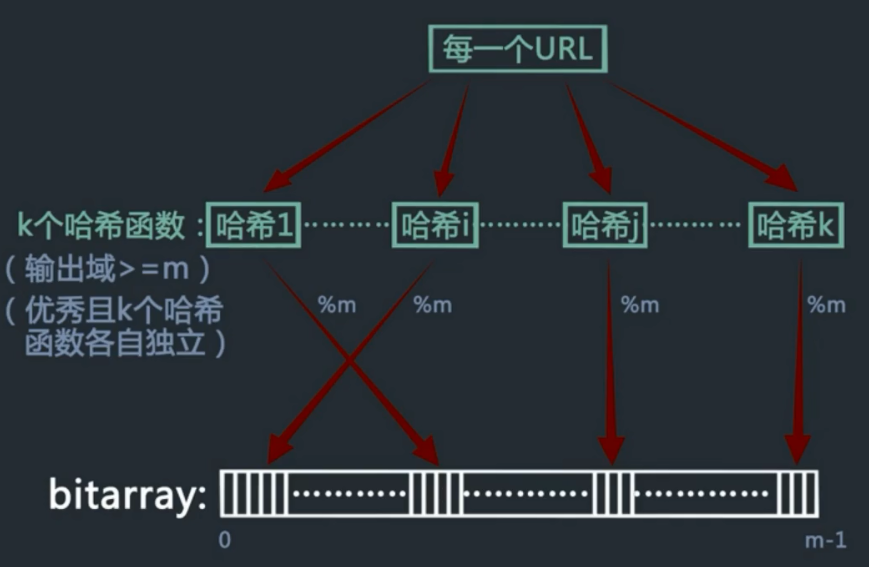
建立k个满足独立的hash函数,将所有的url的值对m取余,再将对应二进制数组位置涂黑。当一个新的url进行同样操作时,如果发现数组中有一个非黑的值即可认为是不在排除的名单中的。
误判的产生主要原因是,二进制数组比较小,基本都被涂黑了。一个新的url生成的哈希对应的二进制值都已经被涂黑,这样就会误判为已经访问的。
二进制数组大小的确定
大小为m,样本数量为n,失误率为p。
$$m=-\frac{n×\ln p}{(\ln 2)^2}$$
$$k=\ln 2×\frac{m}{n}$$
真实的失误率是:
$$(1-\exp^{\frac-{nk}{m}})^k$$