
微积分
夹逼定理:$g(x)<=f(x)<=h(x)$成立,且$\lim_{x\to0}g(x)=A$
$\lim_{x\to0}h(x)=A$,则$\lim_{x\to0}f(x)=A$
极限的定义:$\lim_{x\to0}sinx/x=1$,
分步积分
应用:例如:求$f(x)最小值$

梯度
方向导数:
φ为x轴到方向L的转角
梯度:
梯度方向是函数在该点变化最快的方向。
Jensen不等式
凸函数:

一阶可微
凸函数的切线,一定位于函数图像的下方。
二阶可微
函数满足二阶可微,则为凸函数的条件表示为

常见的凸函数
Jensen不等式
表示凸函数,如果做一个推广:
表示的是x1~xk的线性加权,小于函数值的线性加权。
如果θ表示的概率分布的话,得到下面的结论:
期望的函数<=函数的期望
Jesen不等式非常重要,几乎是所有不等式的基础。
共轭函数
f是$\Bbb{R}^n–>\Bbb{R}$是一个函数,那么f的共轭函数
$$f^*(y)=\sup {x∈dom f}(x^Tx-f(x))$$
以x为斜率,f(x)为截距。
共轭函数是描述在x点处,函数的斜率和截距之间的全体。
共轭函数的性质
- 共轭函数$f^*$是一个凸函数
- 如果g是f的凸闭,那么$g^=f^$
- 如果f是一个凸函数,那么$f^{**}=f$

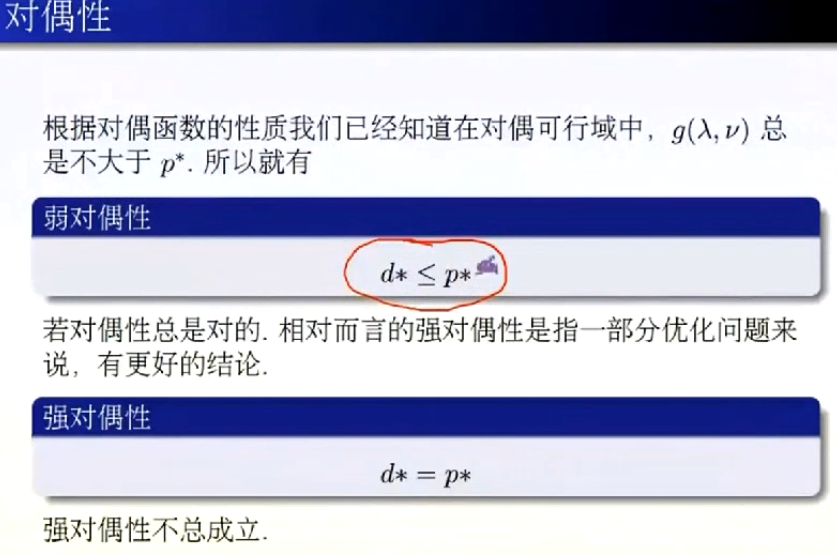
拉格朗日对偶函数




Taylor展开式
$$f(x)=f(x_0)+f’(x_0)(x-x_0)+\frac{f’’(x_0)}{2!}(x-x_0)^2+…+\frac{f^{(n)}(x_0)}{n!}(x-x_0)^n+R_n(x)$$
在$x=0$对$f(x)$进行Taylor展开就是Maclaurin公式
$$f(x)=f(0)+f’(0)x+\frac{f’’(0)}{2!}x^2+…+\frac{f^{(n)}(x)}{n!}x^n+o(x^{n})$$
计算函数值
Taylor公式的应用首先可以计算初等函数值,一般在远点展开
$$\sin x=x-\frac{x^3}{3!}+\frac{x^5}{5!}-\frac{x^7}{7!}+\frac{x^9}{9!}-…+(-1)^{m-1}\frac{x^{2m-1}}{(2m-1)!}+R_{2m}$$
$$e^x=1+x+\frac{x^2}{2!}+\frac{x^3}{3!}+…+\frac{x^n}{n!}+R_n$$
通过泰勒展开,可以对函数值最近似求解。例如下题
k是整数,$2^k$比较好求,$e^r$就可以通过Taylor展开近似的求解
Gini系数公式
Gini系数、熵、分类误差率有下图显示的关系:
熵的定义为:$H(x)=-\sum_{k=1}^K p_k·\ln p_k$
Gini系数利用了$f(x)=-\ln x$在$x=1$处的一阶展开,忽略高阶无穷小,近似得到$f(x)\approx 1-x$,熵就可以近似求解为:$H(x)\approx \sum_{k=1}^K p_k·(1-p_k)$
平方根公式
Taylor公式的另一个应用,可以求解平方根,例如一个数a的平方根的值,$a=x^2$,令$f(x)=x^2-a$,即$f(x)=0$
$$ f(x)=f(x_0)+f’(x_0)(x-x_0)+o(x)$$
在任意点$x_0$做Taylor展开可得:$f(x)=0\approx f(x_0)+f’(x_0)(x-x_0)$—->$x-x_0=\frac{f(x_0)}{f’(x_0)}$—->$x=x_0+\frac{f(x_0)}{f’(x_0)}$
由于$f(x_0)=x_0^2-a$,$f’(x_0)=2x_0$,所以可得$x=\frac{1}{2}(x_0+\frac{a}{x_0})$,$f(x_0)≠0$,给定任意一个x0,求解x1,然后将x1再带入公式求解x2,直到xn-xn+1足够小的时候,作为平方根的解,一般5至6次就可以得到很好的解了。
牛顿法
梯度下降算法
如果要估计θ,而且已经建立了目标函数J(θ),例如最小二乘法建立的目标函数(损失函数):$$J(\theta)=\frac{1}{2}\sum_{i=1}^m(h_{\theta}(x^{(i)})-y^{(i)})^2$$,想计算一个$θ^*$,可以使得$J(θ)$最小。计算方法:随机或者先验的给定$θ$初值,然后沿着负梯度方向迭代,更新$θ$使得$J(θ)$减小,$\theta_j=\theta_j-\alpha·\frac{\partial J(\theta)}{\partial \theta}$,$\alpha$是学习率。
拟牛顿法
牛顿法
通过Taylor展开可不可以做一些处理呢?若$f(x)$二阶导连续,那么$f(x)$在$x_k$处做Taylor展开:
$$\phi(x)=f(x_k)+f’(x_k)(x-x_k)+\frac{1}{2}f’’(x_k)(x-x_k)^2+R_2(x)$$
$$\approx f(x_k)+f’(x_k)(x-x_k)+\frac{1}{2}f’’(x_k)(x-x_k)^2=0$$
$$x_{k+1}=x_k-\frac{f’(x_k)}{f’’(x_k)}$$
这个公式就是牛顿法,本质上是用二次函数做近似,求解二次函数的极值点,而梯度下降法师用一次函数做近似,学习率控制步长。所以二阶收敛性,可以使得目标函数(线性回归、Logistic回归)的问题中收敛速度快。
但是牛顿法要求初始点尽量靠近极小点,否则有可能不收敛。原因:
- Hessian矩阵奇异,也就是二阶导数为零,牛顿方向不存在;
- Hessian非正定,牛顿方向可能是反方向。

拟牛顿法
拟牛顿法的思路,通过近似矩阵代替Hessian矩阵,只要满足矩阵正定,容易求逆。
DFP和BFGS是两种拟牛顿的方法。概率论
概率$P(x)$
分布函数$\Phi(x)=P(x<=x_0)$概率公式
条件概率:$P(A|B)=\frac{P(AB)}{P(B)}$
条件概率的链式法则:$P(a,b,c)=P(a|b,c)P(b,c)=P(a|b,c)P(b|c)P(c)$
全概率公式:$P(A)=\sum_{i} P(A|B_i)P(B_i)$
贝叶斯(Bayes)公式:$P(B_i|A)=\frac{P(A|B_i)P(B_i)}{\sum_{j}P(A|B_j)P(B_j)}$
对于求解碰面问题的概率,可以通过画出x和y所有可能的区域,再求出碰面的范围,再计算面积得到。
如果使用积分,需要考虑两种情况,一个是x<=3,x可以等1个小时,另一个是x>3,x只能等4-x小时。计算稍微复杂一些。
事件独立:$P(AB)=P(A)P(B)$事件A⊥B正交。
条件独立:A⊥B|Z,$P(A,B|Z)=P(A|Z)P(B|Z)$
期望:1、离散型:$E(x)=\sum_{i}x_ip_i$;2、连续型:$E(x)=\int_\infty^{-\infty} xf(x)$(概率加权的平均值)
期望的性质:$E(kX)=kE(X)$,$E(X+Y)=E(X)+E(Y)$,若X和Y相互独立$E(XY)+E(X)E(Y)$
方差:$Var(X)=E{[X-E(X)]^2}=E(X^2)-E^2(X)$
方差的性质:$Var(c)=0$,$Var(X+c)=Var(X)$,$Var(kX)=k^2Var(X)$,若X和Y相互独立$Var(X+Y)=Var(X)+Var(Y)$
协方差:$Cov(X,Y)=E(XY)-E(X)E(Y)$,当X和Y独立时,$Cov(X,Y)=0$。协方差表示两个随机变量变化趋势的度量,大于零表示趋势相同,小于零趋势相反,等于零表示不相关。
协方差的性质:若$Var(X)=\sigma_1^2$;$Var(Y)=\sigma_2^2$,则$|Cov(X,Y)|<=\sigma_1\sigma_2$。当X和Y之间有线性关系时,等号成立。例如:X=aY+b。
相关系数:$\rho_{XY}=\frac{Cov(X,Y)}{Var(X)Var(Y)}$
相关系数的性质:$|\rho_|<=1$
协方差矩阵:当有多个随机向量,每两个随机向量间都可以得到一个协方差,从而组成了协方差矩阵,协方差矩阵时对称阵。$$
\begin{bmatrix}
c_{11} & c_{12} & \cdots & c_{1n} \\
c_{21} & c_{22} & \cdots & c_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
c_{n1} & c_{n2} & \cdots & c_{nn} \\
\end{bmatrix}
$$矩
k阶原点矩$E(X^k)$
k阶中心距$E { [X-E(X)]^k } $
通过矩的定义可以看出,期望是1阶原点矩,方差是2阶中心距。三阶的统计量偏度,四阶统计量是峰度。
偏的方向尾巴更长。
左偏(负偏)|右偏(正偏)
峰度度量的是峰的陡峭程度。通常定义四阶中心矩除以方差的平方减3。减3为了让正态分布的峰度为0,超值峰度为正,称为尖峰态,负为低峰态。它是反应陡峭程度,但需要跟其他结合分析。
契比雪夫不等式:随机变量X的期望$\mu$和方差$\sigma^2$,对于任意正数$\epsilon$$P({|X-\mu|>=\epsilon})<=\frac{\sigma^2}{\epsilon^2}$
大数定理:随机变量X1~Xn相互独立,并且具有相同的期望$\mu$和方差$\sigma^2$,$Y_n=\frac{1}{n}\sum_{i=1}^nX_i$,对于任意正整数$\epsilon$
$\lim_{n\to\infty}P({|Y_n-\mu|<\epsilon})=1$
大数定理为实际应用中频率来估计概率提供了理论依据。正态分布的参数估计,朴素贝叶斯做垃圾邮件分类,隐马尔科夫模型有监督参数学习等。
伯努利定理:是大数定理最早的形式,表争了事件A发生的频率收敛于事件A发生的概率P。
统计学
统计量
样本:$X_1,X_1,…X_n$
样本均值:$\overline{X}=\frac{1}{n}\sum_{i=1}^n(X_i-\overline{X})^2$
样本方差:$S^2=\frac{1}{n-1}\sum_{i=1}^n(X_i-\overline{X})^2$(n-1保证无偏)
k阶样本原点矩:$A_k=\frac{1}{n}\sum_{i=1}^nX_i^k$
k阶样本中心矩:$M_k=\frac{1}{n}\sum_{i=1}^n(X_i-\overline{X})^k$
矩估计
有一些独立同分布的样本,待求均值$\mu$和方差$\sigma^2$,有原点矩表达式是这样的:
$$\begin{cases}
E(X)=\mu \\
E(X^2)=Var(X)+[E(X)]^2=\sigma^2+\mu^2 \\
\end{cases}
$$
根据样本可以求得原点矩:
$$\begin{cases}
A_1=\frac{1}{n} \sum_{i=1}^n X_i \\
A_2=\frac{1}{n} \sum_{i=1}^n X_i^2 \\
\end{cases}
$$
这样就可以求出矩估计的均值$\widehat{\mu}$和方差$\widehat{\sigma}^2$。求得最终的表达式为:
$$\begin{cases}
\widehat{\mu}=\overline{X} \\
\widehat{\sigma}^2=\frac{1}{n} \sum_{i=1}^n (X_i-\overline{X})^2 \\
\end{cases}
$$
极大似然估计
以后完善